Web scraping con C#
Actualmente hay datos a montones y día con dia la información disponible en internet aumenta de forma considerable por ello cuando se requiere extraer gran cantidad de información de un sitio web es preciso ayudarse de técnicas automatizadas como el: Web Scraping.

De acuerdo con la definición de Wikipedia:
Web scraping es una técnica utilizada mediante programas de software para extraer información de sitios web. Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación. (Wikipedia)
El propósito de este articulo es mostrar una forma de extraer datos de una página web y almacenarlos en un base de datos para su posterior uso. Esto lo realizaremos incrustando el navegador Chrome en una aplicación escrita en el lenguaje de programación C#. Para ello requerimos tener el Chrome Driver que es un programa que nos permite controlar Chrome con Selenium y para ello necesitamos instalar los siguientes paquetes de Nuget:
Selenium.WebDriver
Selenium.WebDriver.ChromeDriver
El proceso utilizado para realizar la extracción es:
-
Decidir que información es la que se requiere extraer de un sitio Web. Esta puede ser el precio de un producto, los contactos de un directorio, las imágenes del sitio y un largo etcétera.
-
Inspeccionar la pagina Web objetivo para determinar donde se encuentran los datos para extraer. Para ello puedes utilizar las herramientas de desarrollador de Chrome. Es necesario saber un poco de HTML, CSS y Javascript. En cuanto se posible puedes identificar los elementos HTML por Id, etiqueta, clase,selector css o ruta XPATH. En ocasiones la información puede estar dentro de los atributos.
-
Generar una estrategia para conseguir los datos y programarla.
-
Determinar el formato de salida requerido.Este puede ser desde la impresión en consola hasta una base de datos relacional.
El código
El código de para este articulo esta disponible en el siguiente repositorio esta compuesto por 4 proyectos. Puedes clonarlo con git desde la linea de comando o con el Team Explorer de Visual Studio.
git clone https://github.com/jahbenjah/WebScrappingCSharp.git
Inicialmente pensaba realizar un tutorial paso a paso pero por cuestiones de tiempo no me fue posible. Por lo que el código lo comparto sin muchas explicaciones. Si tienes alguna duda al respecto deja un comentario. Anteriormente ya había escrito como configurar un proyecto para usar Selenium que te puede dar una idea de como configurar tu proyecto con Selenium.
| Proyecto | Tipo | Descripción |
|---|---|---|
| AppCore | Biblioteca de clases .NET Core | Proyecto que contiene entidades y Page Object de la página a extraer datos |
| AppData | Biblioteca de clases .NET Core | Proyecto que contiene el código e acceso a a datos usa Entity Framework Core |
| AppConsole | Proyecto de Consola .NET Core | Usa los dos proyectos anteriores para realizar la extracción de datos. |
| AppTest | Proyecto de pruebas xunit.NET | Utiliza pruebas unitarias para realizar la extracción |
Descripción de la página
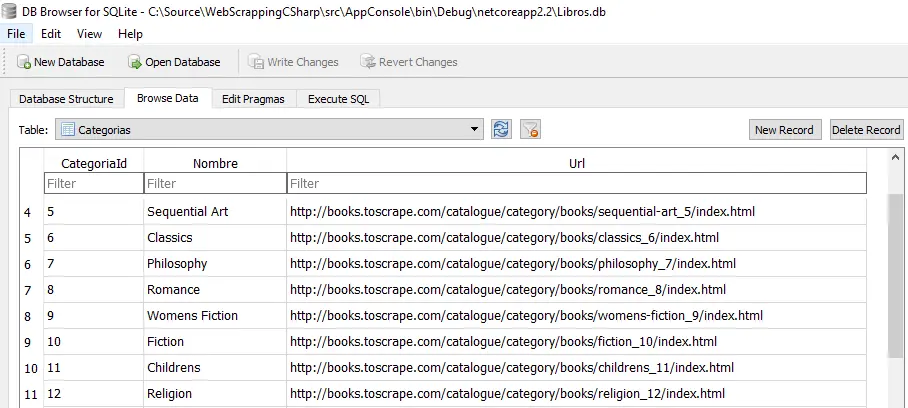
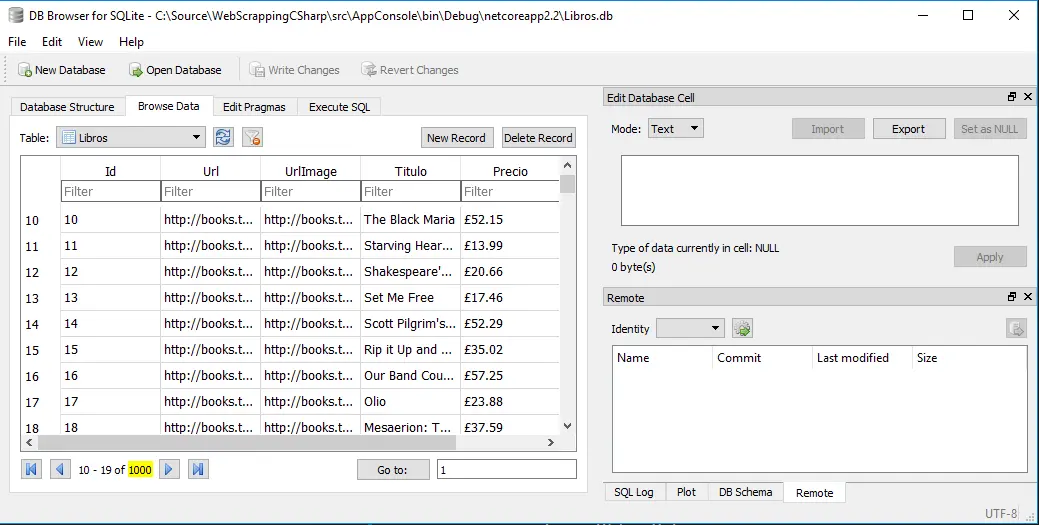
Nuestro proposito es generar una copia local del catálogo de libros y categorías de http://books.toscrape.com esta es una pagina especifica para hacer Web scraping. Contiene un catalogo de 1000 libros con información ficticia y 50 categorías. Con esto en mente ,en el proyecto AppCore creamos un modelo con las clases POCO(Plain Old CLR Objects) Categoria y Libro estas clases lasa utiliza el proyecto AppData para crear la base de datos con SQLite.
public class Libro
{
public int Id { get; set; }
public string Url { get; set; }
public string UrlImage { get; set; }
public string Titulo { get; set; }
public decimal Precio { get; set; }
public int CategoriaId { get; set; }
public Categoria Categoria { get; set; }
}
public class Categoria
{
public int CategoriaId { get; set; }
public string Nombre { get; set; }
public string Url { get; set; }
public List<Libro> Libros { get; set; }
}
Para crear la base de datos usamos el conector para SQLite y el comando dotnet ef database create. Para visualizar y consultar una base de SQLite usamos la aplicación DB Browser for SQLite.
El catalogo esta compuesto de 50 paginas en cada pagina se muestran 20 libros. Cada uno de estos libros tiene una pagina donde se muestran los detalles del mismo. Las paginas del catalogo tiene la siguiente estructura http://books.toscrape.com/catalogue/page-n.html donde n es 1 ….50. Para extraer los datos de los 1000 libros es necesario acceder a cada una de las 50 paginas del catalogo conseguir la liga de cada uno de los libros para después acceder a cada uno y conseguir los datos requeridos.
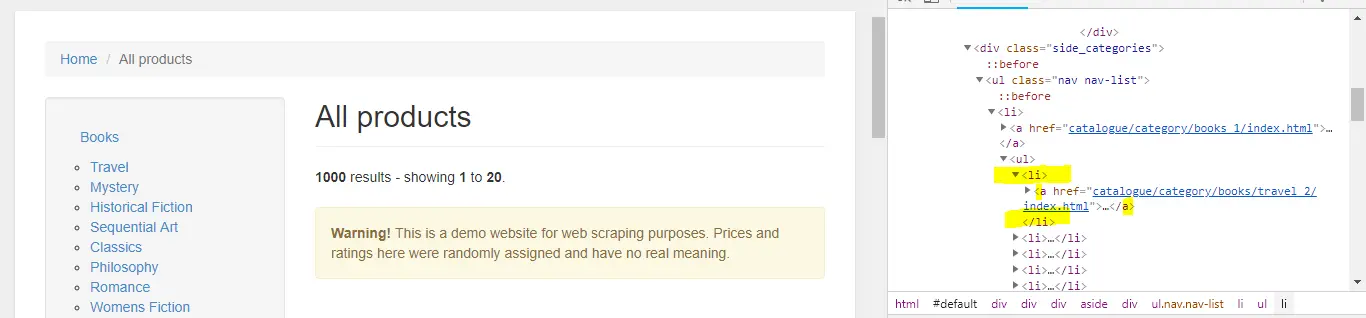
Las categorías se encuentran en la barra lateral de las paginas del catalogo por lo que solo es necesario navegar por la primera pagina y extraer los datos de las categorías (Id, Nombre , Url).
Extracción categorías
Necesitamos una forma de generar las url del catalogo. Una forma de solucionar esta parte del problema es creando un método que lo realice por nosotros:
public static List<string> GetCatalogoUrls()
{
List<string> urls = new List<string>();
for (int i = 1; i <= 50; i++)
{
urls.Add($@"http://books.toscrape.com/catalogue/page-{i}.html");
}
return urls;
}
Otra parte del problema es ordenar a Chrome para que navegue por estas urls. Para esto no ayudara Selenium WebDriver y ChromeDriver. El método GetDriver configura las opciones que nos permiten ejecutar Chrome y controlarlo desde C#.
private static IWebDriver GetDriver()
{
var user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.50 Safari/537.36";
ChromeOptions options = new ChromeOptions();
//Descomenta ela siguiente linea para usar el mode headless de Chrome
//options.AddArgument("--headless");
options.AddArgument("--disable-gpu");
options.AddArgument($"user_agent={user_agent}");
options.AddArgument("--ignore-certificate-errors");
IWebDriver driver = new ChromeDriver(Directory.GetCurrentDirectory(), options);
return driver;
}
Con esto es posible controlar una instancia de Chrome hacerlo navegar por la url deseada. Como ejemplo podemos hacer que navegue por las 50 url del catalogo. Esto es lo que realiza el método NavegarPorElCatalogo
public static void NavegarPorElCatalogo(IWebDriver driver)
{
foreach (var url in GetCatalogoUrls())
{
driver.Navigate().GoToUrl(url);
}
}
Si ejecutas e l método NavegarPorElCatalogo veras que Chrome empieza a navegar por cada una de las urls que devuelve el método GetCatalogoUrls.
Las última parte del problemas son es extraer los datos y guardarlos.
La responsabilidad de los clases Catalogo y DetalleLibro es extraer los elementos HTML regresar los datos necesarios
public class Catalogo
{
private IWebDriver _driver;
public Catalogo(IWebDriver driver)
{
if (driver.Title != "All products | Books to Scrape - Sandbox")
{
throw new ArgumentException("El titulo no corresponde a una pagina del catalogo");
}
_driver = driver;
}
public List<Categoria> ObtenerCategorias()
{
List<Categoria> categorias = new List<Categoria>();
var links = _driver.FindElements(By.CssSelector("#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a"));
foreach (var item in links)
{
if (item.Text.Length > 0)
{
var url = item.GetAttribute("href");
var inicio = url.LastIndexOf('_') + 1;
var largo = url.LastIndexOf('/') - inicio;
var category = new Categoria()
{
CategoriaId = Convert.ToInt32(url.Substring(inicio, largo)),
Nombre = item.Text,
Url = item.GetAttribute("href")
};
categorias.Add(category);
}
}
return categorias;
}
public List<string> ObtenerUrlLibros()
{
List<string> urls = new List<string>();
var links = _driver.FindElements(By.XPath("//*[@id='default']/div/div/div/div/section/div/ol/li/article/h3/a"));
foreach (var link in links)
{
urls.Add(link.GetAttribute("href"));
}
return urls;
}
public string GetTitulo()
{
return _driver.FindElement(By.TagName("title")).Text;
}
public void Siguiente()
{
var siguiente = _driver.FindElement(By.CssSelector("#default > div > div > div > div > section > div:nth-child(2) > div > ul > li.next > a"));
siguiente.Click();
}
public void Anterior()
{
var anterior = _driver.FindElement(By.CssSelector("#default > div > div > div > div > section > div:nth-child(2) > div > ul > li.previous > a"));
anterior.Click();
}
}
Finalmente para almacenar las categorias en la base de de dato creamos el metodo GuardarCategorias
public static void GuardarCategorias()
{
var driver = GetDriver();
driver.Manage().Window.Maximize();
foreach (var url in GetCatalogoUrls().Take(1))
{
driver.Navigate().GoToUrl(url);
Catalogo catalogo = new Catalogo(driver);
var cate = catalogo.ObtenerCategorias();
using (var db = new AppData.AppContext())
{
foreach (var cat in cate)
{
db.Categorias.Add(cat);
db.SaveChanges();
}
}
}
}
Si abrimos la base de datos SQLite veremos las categorias.
Extración detalle libros
Para extraer los datos del detalle de cada libro utilizamos la clase DetalleLibro que intenta implementar el patron PageObject.
public class DetalleLibro
{
private IWebDriver _driver;
public DetalleLibro(IWebDriver driver)
{
if (!driver.Title.Contains("| Books to Scrape - Sandbox"))
{
throw new ArgumentException("El titulo no corresponde a una pagina del catalogo");
}
_driver = driver;
}
public string GetTitulo()
{
return _driver.FindElement(By.CssSelector("#content_inner > article > div.row > div.col-sm-6.product_main > h1")).Text;
}
public string GetPrecio()
{
return _driver.FindElement(By.ClassName("price_color")).Text;
}
public string GetUrlImagen()
{
return _driver.FindElement(By.CssSelector("#product_gallery > div > div > div > img")).GetAttribute("src");
}
public string GetCategory()
{
return _driver.FindElement(By.CssSelector("#default > div > div > ul > li:nth-child(3) > a")).Text;
}
public int GetCategoryId()
{
var categorylink = _driver.FindElement(By.CssSelector("#default > div > div > ul > li:nth-child(3) > a")).GetAttribute("href");
var inicio = categorylink.LastIndexOf('_') + 1;
var largo = categorylink.LastIndexOf('/') - inicio;
return Convert.ToInt32(categorylink.Substring(inicio, largo));
}
public Libro GetDetallesLibro()
{
Libro libro = new Libro()
{
CategoriaId = GetCategoryId(),
Precio = GetPrecio(),
Titulo = GetTitulo(),
UrlImage = GetUrlImagen(),
Url = _driver.Url
};
return libro;
}
Para guardar en la base de datos usamos el siguiente código
static void Main(string[] args)
{
var driver = GetDriver();
driver.Manage().Window.Maximize();
foreach (var url in GetCatalogoUrls().Skip(1))
{
driver.Navigate().GoToUrl(url);
Catalogo catalogo = new Catalogo(driver);
var links = catalogo.ObtenerUrlLibros();
foreach (var link in links)
{
driver.Navigate().GoToUrl(link);
DetalleLibro detalleLibro = new DetalleLibro(driver);
using (var db = new AppData.AppContext())
{
db.Libros.Add(detalleLibro.GetDetallesLibro());
db.SaveChanges();
}
}
}
ReadLine();
}
Aqui es recomendable usar el modo headless de Chrome . Puedes descomentar la línea options.AddArgument("--headless"); GetDriver del método para que no se veas el navegador.
Para llevar
Un gran poder conlleva una gran responsabilidad. tío Ben
-
La mayoría de las páginas tienen un archivo llamados robots.txt que controlan el accesos a los robots que es importante que conozcas y respetes. Mira el archvio robots.txt de aspnetcoremaster.com.
-
Siempre es bueno apegarse a un Código de ética por ejemplo el de la ACM Código de Ética y Conducta Profesional de ACM.
-
Es probable tu IP pueda sea bloqueada si se observa un trafico constante a una determinada página.
-
La refactorización del código se constante ya que las paginas pueden cambiar.
-
Aquí te mostramos la ruta fácil y feliz. Es una extracción real encontraras muchas excepciones que tendrás que manejar en tu código.
-
Para interacturar con algunas paginas debes saber Javascript y como ejecutarlo desde Selenium.